SageMaker Onboarding Overhaul
A complete overhaul of the SageMaker onboarding experience.
Company
Amazon Web Services
Role
Frontend Software Engineer
Timeline
6 months
Launch
2022
NDA
Wherever possible, I have anonymized or generalized information to avoid breaching NDA, so some details may be sparse.
Background
Sagemaker is an Amazon Web Services (AWS) product focused on providing a managed interface for data scientists, engineers, and machine learning practitioners to perform analyses and process data. The Console team is charged with maintaining the user interface that allows users to access Sagemaker and create and manage resources.
The Problem
Onboarding is one of the first interactions that users have with a product, and sometimes is the reason why someone signs up or does not. The existing Sagemaker Console onboarding process relies on a single page filled with form components which all have to load at the same time, creating long loading times and increasing user dropout. From a business perspective, user dropout represents lost revenue, meaning that improvements to this onboarding flow directly leads to higher profits for the Sagemaker organization.
Scoping
I worked with our UX designer on this project to better understand how I could better understand this project holistically, from both an engineering and design perspective. One of the key points she communicated to me was the Doherty Threshold, the idea that when a computer and user interact at a pace of under 400ms, productivity is increased. This was one of the key metrics we aimed to achieve during development, as the existing page took seconds (thousands of milliseconds!) to load. There was definitely room for improvement.
This project broke down into 2 distinct parts: rearranging the existing single-page flow into a multi-step form, and implementing components specific to supporting RStudio functionality.
The main point of changing the onboarding flow to multi-step was to decrease load times, as the number of components loading per step of the form would be much smaller than loading them all at once. For reference, the original flow had around 15 components on the page that had to load, while each page of the new flow had a maximum of 4.
We chose to split the form steps into logical groups. For example, the first step covers username and password setting, the next storage configuration using the S3, one for RStudio, and so on. Chunking content in the lengthy onboarding process easier to process, and increased our overall rate of completion in post launch testing.
For the RStudio specific components, we had initially budgeted about a sprints worth of time to completion. However, during development, we found that the RxJS API layer that was being used to retrieve data on page load was not very adaptable. In short, code retrieving data was chained together in a manner that was incredibly difficult to test and change to fit the needs of the RStudio API calls. This fault required a choice between working with brittle code or rewriting the legacy code to ensure projects in the future had a better foundation to start on. We decided on the latter, and rewrote the majority of the legacy code to be atomic and composable, allowing for easier integrations in the future. The reason behind making this decision was that we had a major project after this one in the pipeline, and kicking the API issue further down the timeline would have only worsened the problem.
Testing
I made sure to test the code I wrote as I went, with at least one end-to-end click test for each major component and logical section of the onboarding flow. This was complicated by the fact that our team was moving from a Jest to a Cypress based testing infrastructure, but sticking to Cypress and working out any initial configuration issues smoothed this potential problem over pretty quickly.
Further integration testing was done in our team’s deployment pipeline, which helped catch overarching issues that may break downstream systems or our own pages. Thankfully, most issues were caught in local development, and the few that made it to integration testing came down to inconsistent formatting specifications on our code review commit hook (in short, the commit hook didn’t properly run ESLint on committed code, which then broke the staging environment)
Delivery
Our team had planned to complete each phase of this project in sprints, following Agile methodology. After the majority of the functionality was completed, we deployed our code to a beta (post staging) environment that could be shared with stakeholders on other teams in order to demo the end to end flow and catch any issues before releasing worldwide. Our final rollout took about a week, starting with North American regions and moving to Asia and the EU. I was oncall for the team at the time, and handled deployment monitoring and testing using an internal Amazon tool.
Screens
The final flow is live now on AWS, and can be viewed when creating a new Sagemaker Domain in Studio. Some screens are included below.
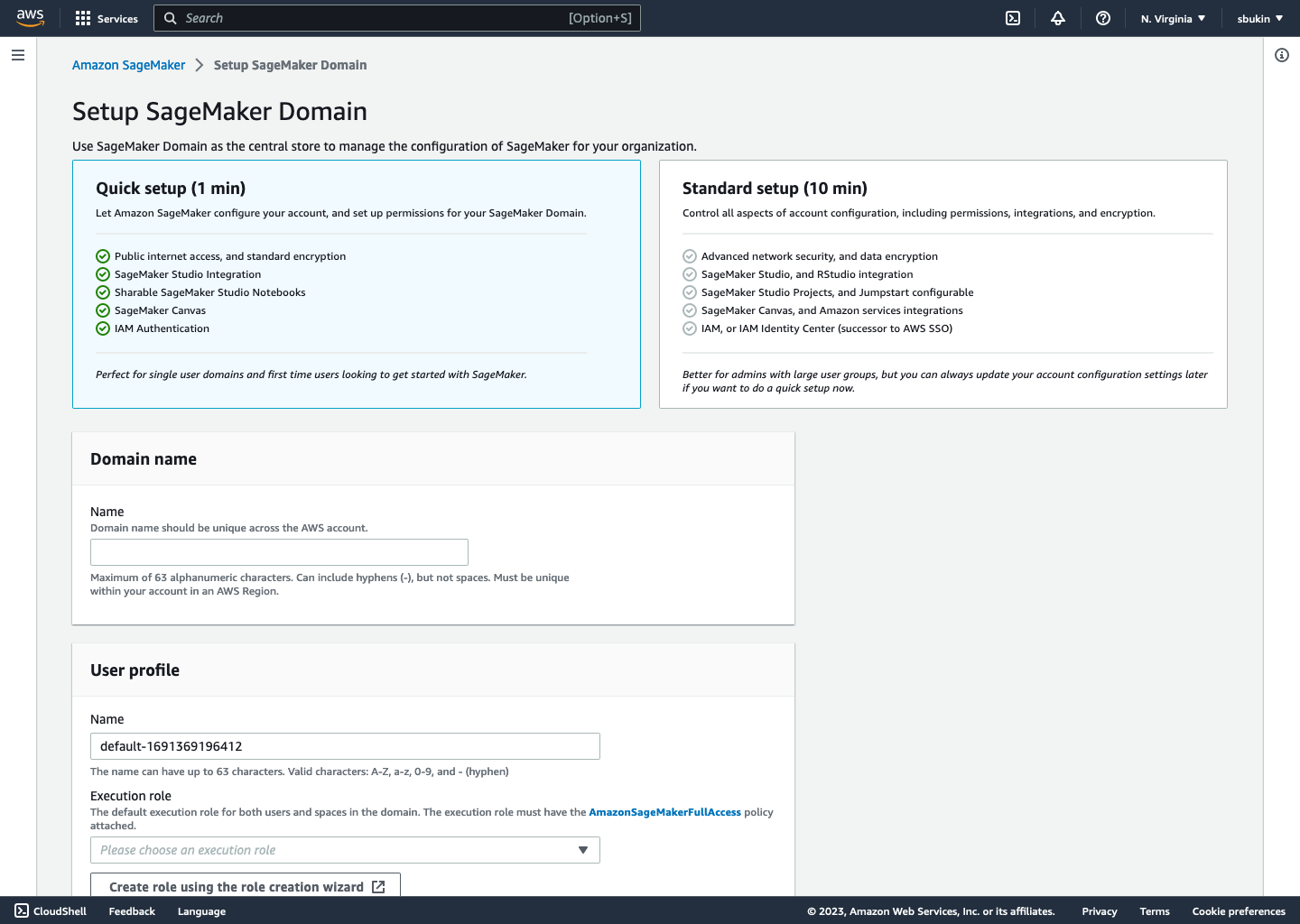
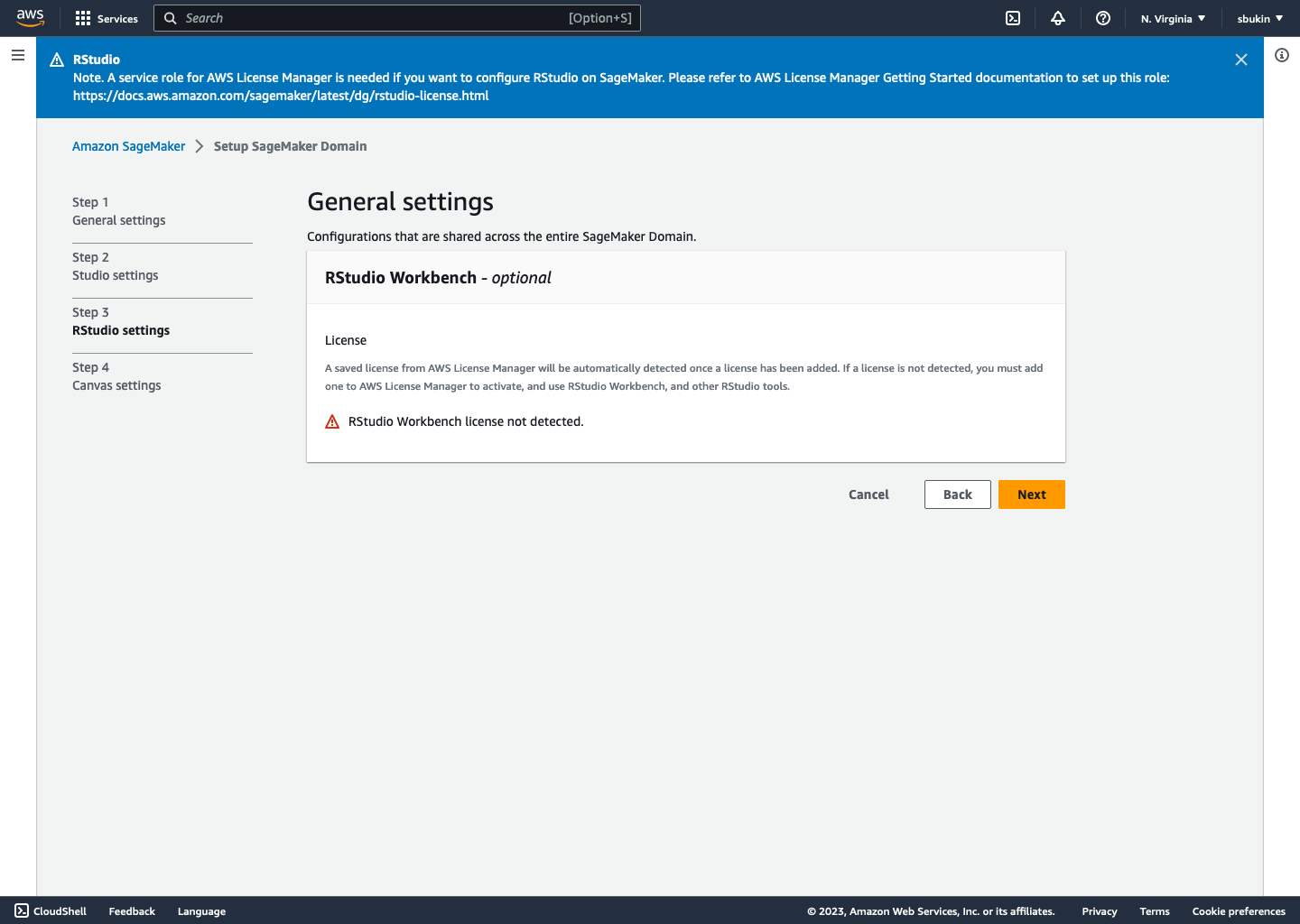
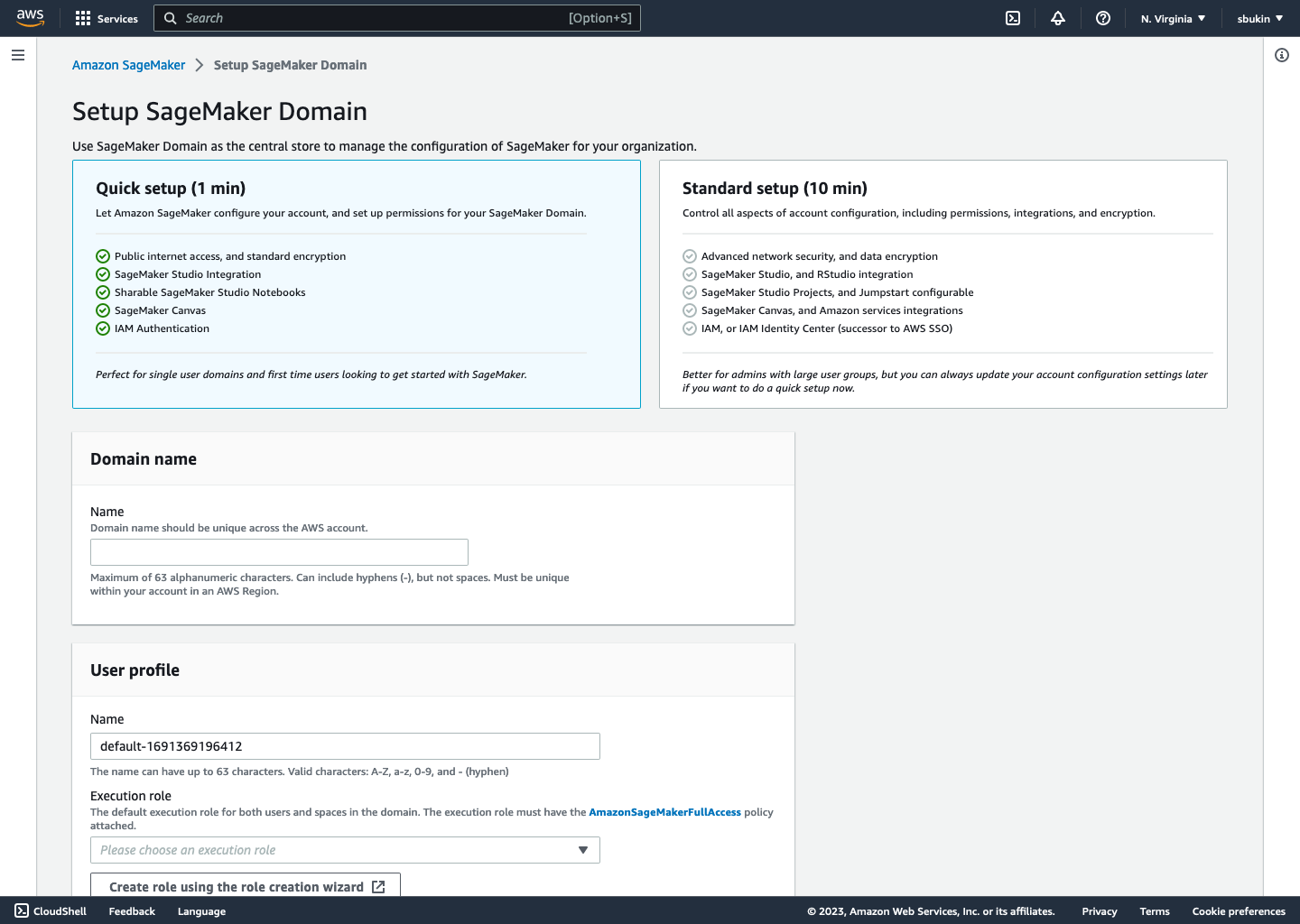
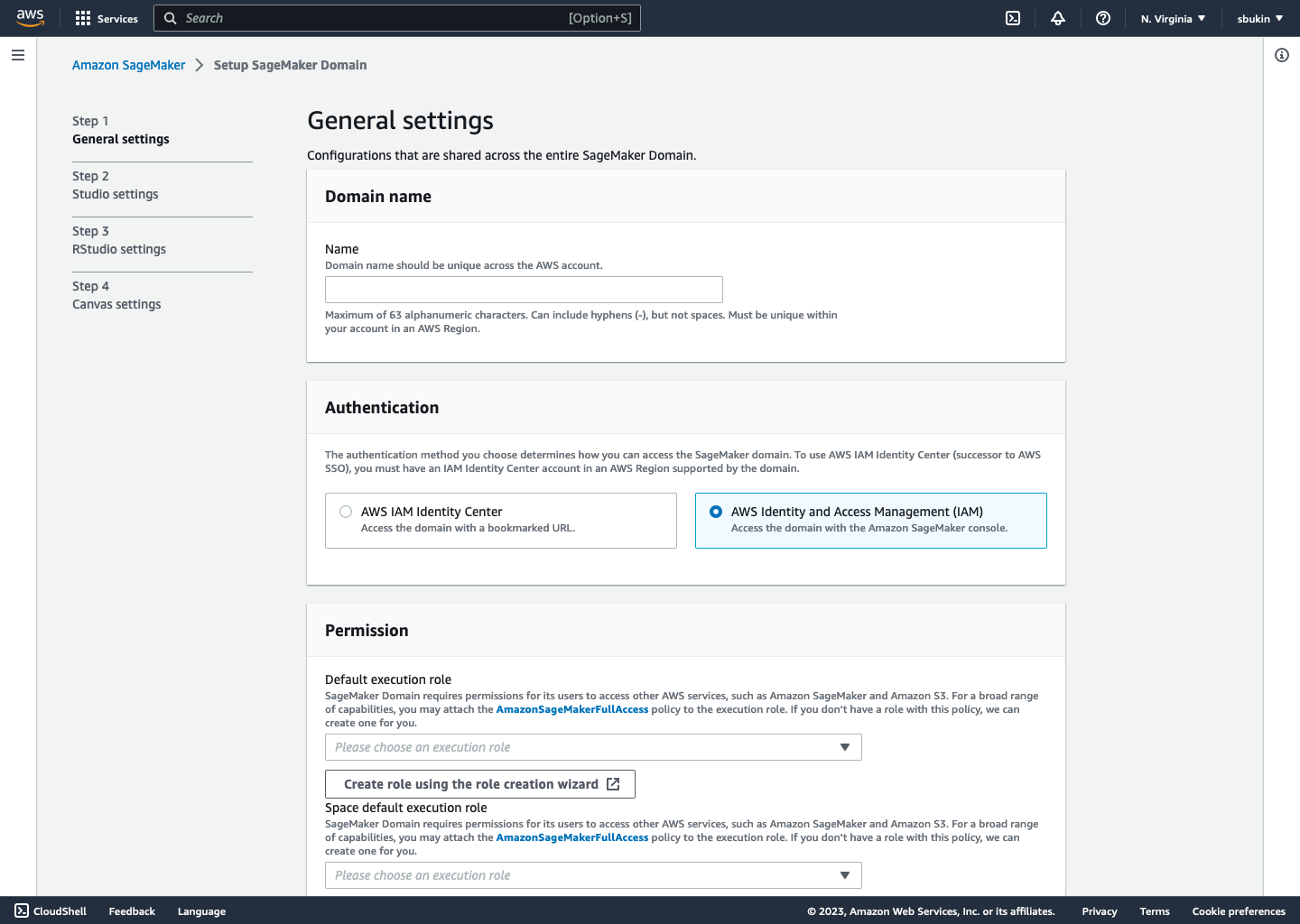
Learnings & Takeaways
Raising issues early helped save time later
Our team ran into plenty of time sinks in this project, from API issues to deployment and testing breakage. Practicing honesty and upfront time estimation kept our product team aware of changes and able to adapt, which eventually led to satisfying project delivery (with only a few sleepless nights for oncall).
API layer changes always need more time
Though I was able to detect the API layer issues relatively early in the development process, budgeting time properly for fixing them was a different challenge entirely. Taking into account current testing setups would have made a large difference here, as a lot of the planning for this fix was done with the assumption that the existing test coverage was good (it was not).
Sweat the small stuff
This project had its fair share of larger issues, like the API layer changes, but many smaller papercuts caused additional headaches for our team. For example, one of our presubmit hooks was formatting code differently than our local workspaces, meaning that testing suites would break in integration through no fault of the engineer. My takeaway from this is to attempt to smooth over small annoyances in the space between projects or during “fixit” days, as these quick wins can add up when considered in the timeframe of a large project like this one.